VRで自分の手がオブジェクトを貫通しないようにして"ものに触っている感"を出す
こんにちは!新しく代表になりました学部二年のにとです。この記事はA-PxLのアドベントカレンダーに向けて執筆しました。最近はHalf-Life:AlyxやGreen Hell、ルインズメイガスなどいろんなVRゲームで遊んでいますが、やはり没入感を高める細かい工夫がたくさんあってすごく参考になりますね。今回は地味ながらも没入感がアップする"ものに触っている感"を作っていこうと思います。

環境
HMD : Meta Quest2
Unity : 2021.3.11f1(URPを導入)
XR Interaction Toolkit : 2.0.4
作るもの
今回はVR内の手でオブジェクトに触れて、貫通しないようにしようと思います。
赤丸がコントローラーの位置
youtu.be
今まではXR Interaction Toolkitが提供しているXR Originのアンカーの子オブジェクトに手を配置していたんですが、そうするとVRで壁などの動かないオブジェクトに触れようとするとコライダーをつけていても貫通してしまいます。意外と盲点でした。
実装方法を考える
作るにあたって3つの実装方法案を考えました。
Rayを使ってオブジェクトとの距離を測り、手が埋まらないようにtransformを変えていく
Rigidbodyとコライダーを信じてオブジェクトと手を接触させる
- Jointを使う
まず1は主にベクトルの計算をしていくのですが、オブジェクトがただの平面のときはよくても曲面や凸凹面になるとややこしくなってしまったのでダメでした。
2に関しては簡単に作れたのですが、↓のように挙動が安定しないのと、オブジェクトに触れた後に手の位置が変わってしまうなどの不具合があってダメでした。

3のJointを使う方法が一番うまくいったので紹介しようと思います。
Fixed Jointを使って実装する
1. XR Interaction ToolkitでVR環境を作る
まずはXR Interaction Toolkitの導入をしていきます。
いつも参考にさせていただいている記事↓
framesynthesis.jp
これで環境が整ったらXR Originをシーンに配置します。一応移動とスナップターンができるよう、XR Originに
- Locomotion System
- Continuous Move Provider
- Snap Turn Provider
をアタッチします。Continuous Move ProviderとSnap Turn ProviderはAssets>Samples>XR Interaction Toolkit>2.0.4(バージョン)>Starter Assetsの中の「XRI Default Continuous Move」と「XRI Default Snap Turn」をインスペクタにドラッグアンドドロップすると細かい設定をせずにアタッチできます。
こんな感じになれば大丈夫です。
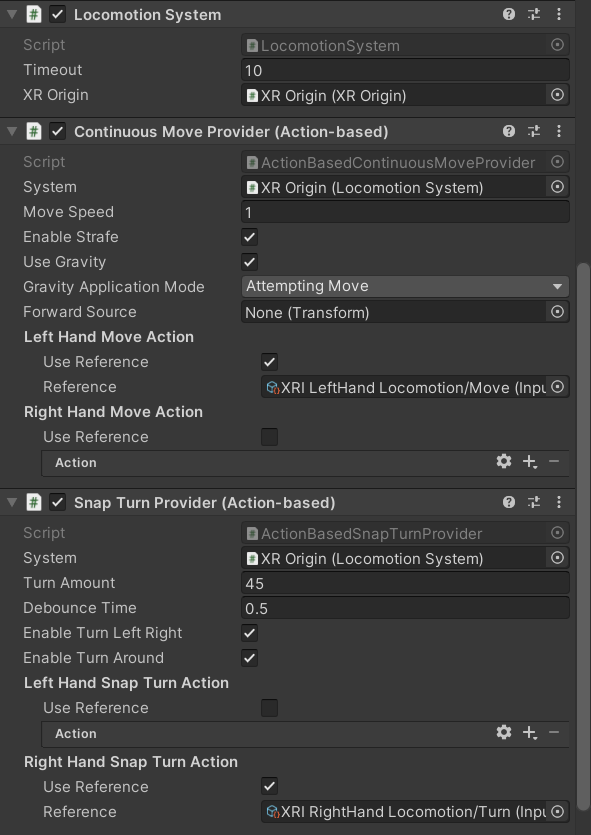
XR Originを入れるところ忘れずに!
2. シーンに手のモデルを配置する
次に手をシーンに配置します。無料のモデルがAsset Storeになかったので「手 3Dモデル フリー」などと調べて出てきたものを適当に追加しました。手の位置や大きさを調整していい感じになったらOKです。(QuestLinkなどで実行しながら調整して値をコピーし、実行停止してペーストするのがラク)
今回はオブジェクトに触れる手を作るので、RigidbodyとColliderも追加しましょう。また、RididbodyのConstrainsのFreeze Rotationのxyz全てにチェックを入れます。

僕が使ったモデルは軸がおかしかったので空のGameObjectを作ってその中に手のモデルを入れました。(画像は空のGameObjectのインスペクタ)
3. Fixed Jointを設定する
次にFixed Jointを追加していきます。
XR Originの子オブジェクトの中の「Left Hand Controller」と「Right Hand Controller」にFixed Jointコンポーネントを追加します。追加されたRigidbodyのIs Kinematicにはチェックを入れておきましょう。

ここでFixed JointのConnected Bodyに手を入れても動くのですが、動きがガクガクしてしまうので、オブジェクトに触れている間だけ接続して、触れていない間はコントローラーを追従するようにします。
4. スクリプトを書く
手のモデルをコントローラーに追従させ、オブジェクトに触れたらFixed Jointに接続するコードを書いていきます。
using UnityEngine; public class HandJointBehavior : MonoBehaviour { [SerializeField] private Transform _controller; private bool _isTouch; private Rigidbody _rigidbody; private FixedJoint _joint; private void Start() { _rigidbody = GetComponent<Rigidbody>(); _joint = _controller.GetComponent<FixedJoint>(); } private void Update() { // 回転は常に追従 transform.rotation = _controller.rotation; // 触れていないときはコントローラーを追従する if (!_isTouch) { transform.position = _controller.position; } } private void OnCollisionStay(Collision other) { _isTouch = true; _joint.connectedBody = _rigidbody; // FixedJointに接続 } private void OnCollisionExit(Collision other) { _isTouch = false; _joint.connectedBody = null; // FixedJointから切断 } }
シンプルに実装できました。
最後に、書いたスクリプトを手のオブジェクトにアタッチします。アタッチしたらインスペクタのControllerに対応するコントローラーを入れます。

完成
さいごに
VR内で手を衝突させることで現実の手の位置とのズレが生じるのですが、違和感なく手がオブジェクトに触れている感じを表現することができました。触れたときにSEを出す、触れている間はコントローラーを振動させるなどでさらに没入感を得られると思います。
今年は勉強会の講師やチーム開発のリーダー、IVRCなど初めてのことをたくさん経験し、大きく成長できた一年でした。これからはA-PxLの代表としてより一層がんばっていこうと思います。そして来年はXRの面白さをもっと知り、いろいろな技術に触れていきたいです。
2023年もよろしくお願いします!
2022年A-PxL活動報告
こんにちは、元代表の土鍋です。 この記事は全国学生VRサークル活動報告大会アドベントカレンダー21日目です。
さて、2022年も終わりということで今年のA-PxLの活動を振り返ろうと思います。
UnityThon
1月に会津大の他ゲーム系サークルと合同で開催した勉強会付きハッカソンです。
詳しくはこちらのブログに書いたのでよろしければご覧下さい。
新入生向けXR体験会
4月は新入部員を獲得するためにVR体験会を実施しました。
自分たちの作品や有名なVRゲームなどを体験してもらってまずはXRに興味を持ってもらい、XR体験会を実施しました。

初心者向け勉強会
5月~7月
新入部員向けにUnity、C#、Gitの勉強会を実施しました。
一人である程度ゲームが作れるレベル(少なくともググりながら)まで教えました。また、大学の授業より早くプログラミングに触れられるので予習にもなった思います。
IVRC
5月~11月
サークルメンバー内の興味がある人でチームを結成し、挑戦しました。長期間に渡る開発でしたが、「審査委員会特別賞」を頂きました。
IVRCの経験についてはこちらにまとめました。
またハードウェアチームの詳しい解説はこちら。
学園祭に向けた開発
8月~10月
サークル内でチームを結成して、10月の学園祭に向けて作品を制作しました。
こでらんに文化祭
11月5日に福島市のまちなか広場で開催されたNHK福島主催のイベントに出展しました。
ラジオ出演
11月11日に私土鍋がNHK福島「こでらんに5next」に出演しました。 サークルの活動やIVRCの話などをしました。
コミックマーケット
12月31日
学園祭に向けて開発した作品をブラッシュアップして無料頒布します。
まとめ
2022年のA-PxLは学内外で活動できた充実した一年でした。
反省としてはこのブログの記事が少ないことでしょうか…部員が個人ブログをもっているので、なかなかこっちに書けないんですよね。月イチで持ち回りでブログを書くとかにしたら良いかもですね。
私は今年の11月に代表の座から退き、次の代表はにと君が務めます。
2023年のA-PxLをよろしくお願いします!
Unity Hub 3.0のインストール方法と使い方
代表の渡辺です。Unity Hub 3.0のインストール方法の解説が少なかったのでまとめました。
Unity Hub 3.0について
最近、2.0からバージョンアップしたため、まだ不安定なところがあるかもしれません。
インストール方法
Unity Hubのインストール
以下のサイトからUnity Hubをダウンロードして実行
Windowsの人は「Download for Windows」をクリック

Macの人はスクロールして「Download for Mac」をクリック。

ダウンロードしたファイルを実行すると、UnityHubが開きます。
アカウント登録
- 画面左上からCreate account
- webサイトが開く
- 必要情報を入力してアカウント登録


ライセンスについて
画面左上からManage licensesからライセンス管理
基本、Personalで良いと思います。
Student Planに申し込めばProを使えます。

Unityのインストール
- Installs→Install Editor
- 基本的には一番上のLTSをインストール
- モジュールの追加(必要なものを追加)
- Continueでインストール
※チーム開発ではバージョンを揃える必要があるのでその場合はArchive→download archiveで必要なバージョンを探す。


プロジェクトの作成
- Project→New Project
- テンプレートを選ぶ(今回は3D)
- プロジェクト名を入力
- 保存先を設定
- Create project
※Unity Hubの設定からデフォルトの保存先を設定しておくと良い

変更履歴
- 2023/5/10 いくつか写真と説明追加しました。
2021年の学園祭にて発表した作品と2022年のA-PxLの展望
あけましておめでとうございます!
昨年11月から代表になりました学部2年の渡辺です。
本当は昨年末に総括的な形でブログを書きたかったのですが、12月が忙しく年を跨いでしまいました...
2021年も2020年に引き続きコロナ禍で思うような活動がし辛い状況でしたが、2020年よりは対面での活動も増え、有意義なサークル活動ができたと思います。と同時に様々な反省点があったのでそれらを踏まえて2022年の活動をしていきたいと思います。
学園祭にて発表した作品
チーム Struck Out
様々な方向から出現する敵にボールを投げて倒していくゲームです。
チーム しろT
フィールドにあるアイテムを集めて武器をクラフトし、次々に出現する敵を銃や剣で倒すゲームです。
2022年の展望
2022年はA-PxLを飛躍させる年にしたいと考えています。具体的には、サークル外や大学外での活動を増やしたいと考えています。
2022年度、会津大学の技術系サークル同士で協力し盛り上げようという動きがあり、我々A-PxLも参加しようと考えています。勉強会の開催、様々なハッカソンの実施などをサークルの垣根を跨いで参加できるようにしたり、企業や他大学の人を呼んだLT会の実施、インターンへの積極的参加など新たな試みを実施する予定です。また、大学外の活動として展示会や即売会などのイベントへの参加も積極的に行いたいと思っています。
このサークルに所属してよかったと思えるサークルを目指して頑張ります。 これからもA-PxLをよろしくお願いします。

Unity(C#)でのデリゲート/イベントのつかいかた
こんにちは! 夏の暑さにやられている修士1年の橋本です。本当に暑い日が続いていますよね。いつから日本はこうなってしまったのやら。
さて、タイトルの通り今回は Unity(C#) でのデリゲートとイベントについての話をしていこうと思います。対象読者は 「デリゲート? なにそれ美味しいの?」な人や「デリゲート/イベントの利用方法は知っているが、使いどころが分からん」みたいな人です。内部実装がどうなっているのかとか、上級者向けの使い方みたいな沼に突っ込んだような話はしないのでご注意ください。

(Visual Studio Code では event は雷アイコンとなっているため雷のイラストを配置してみました。)
目的
この記事での目的は以下の3つです。
デリゲート
デリゲートのイメージ
デリゲート、何だか刺々しいような響きの言葉ですね。デリゲート(delegate)は「委譲する」みたいな意味を持つ英単語です。そして、C#におけるデリゲートとは「メソッドの参照を保持するための型」を意味します。他のプログラミング言語では「関数型」と呼ばれたりするものです。イメージ的には、メソッドを格納するための機能みたいな感じですかね。以下のサンプルコードを見てみましょう。
using UnityEngine; // デリゲートの型を新しく定義 delegate void MyDelegate(); public class DelegateSample : MonoBehaviour { void Start() { // int型の変数を作成し、10で初期化する int i = 10; Debug.Log(i); // 違う値を代入 i = 3; Debug.Log(i); // デリゲート型のインスタンスを生成し、メソッド 「こんにちは」 で初期化。 MyDelegate md = こんにちは; // デリゲートを介してメソッドを呼び出す md(); // 違うメソッドを代入 md = さようなら; md(); } void こんにちは () { Debug.Log("Hello!"); } void さようなら() { Debug.Log("Goodby!"); } }
実はC#って変数名やメソッドなどに日本語が使えるんですよね。使う機会は全くありませんケド...。
実行結果は以下のようになります。

「デリゲートとはメソッドを格納するための機能だ」という意味が何となくわかったのではないでしょうか。
デリゲートの宣言
上のコードでは、クラスのブロックの上でデリゲート型の宣言をしていますね。
// デリゲートの型を新しく定義 delegate void MyDelegate();
デリゲート型を宣言するときは以下のようにします。
delegate 戻り値の型 デリゲート名 (引数リスト);
初めて見るとなんか分かりにくい感じがしますね。例えば、以下のように宣言したデリゲート型があるとします。
delegate int MyDelegate(int a, int b);
この場合、MyDelegate型は 「int型の引数を2つ受け取ってint型の値を1つ戻すメソッド」を格納することができるデリゲート型となります。では、「string型の引数を1つ受け取って戻り値が void のメソッド」を格納するためのデリゲート型はどうなるでしょうか。もうお分かりでしょう。
delegate void MyDelegate(string str);
デリゲートの利用
宣言したデリゲートはintやstringといった組み込み型と同じように使用することができます。インスタンスメソッド、staticメソッドのどちらも格納することが可能です。
// デリゲート型のインスタンスを生成し、メソッド 「こんにちは」 で初期化。 MyDelegate md = こんにちは; // デリゲートを介してメソッドを呼び出す md(); // 違うメソッドを代入 md = さようなら; md();
デリゲートに登録されたメソッドを呼び出すときはデリゲートインスタンスの変数名()のようにします。普段メソッドを呼び出すのと同じ使い方です。
ただし、1点だけ特殊な性質があります。なんと、デリゲートは複数のメソッドを登録(格納)することができるのです!
using UnityEngine; delegate void MyDelegate(); public class DelegateSample : MonoBehaviour { void Start() { MyDelegate md = こんにちは; md += さようなら; md(); md -= さようなら; md(); } void こんにちは() { Debug.Log("Hello!"); } void さようなら() { Debug.Log("Goodby!"); } }
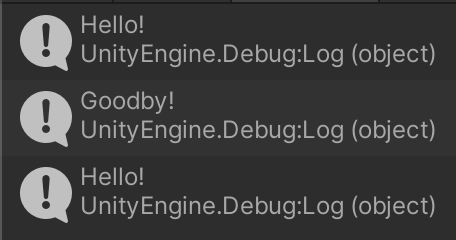
デリゲートインスタンスはメソッド「こんにちは」で初期化されていますが、その後 += 演算子によりメソッド「さようなら」が追加で登録されています。この状態でデリゲートを起動するとこのデリゲートに登録された全てのメソッドが呼び出されます。このように、複数のメソッドをデリゲートに登録することをマルチキャストデリゲーションと呼んだりします。
なお、登録した順番でメソッドが呼ばれます。すなわち、並列処理ではなく逐次処理です。もし戻り値があるメソッドを複数登録した場合、そのデリゲートの戻り値は一番最後に登録されたメソッドの戻り値となります (戻り値があるメソッドを複数登録したデリゲートの戻り値を利用するシーンなんてないとは思いますが)。
また、登録したメソッドは -= 演算子により登録をキャンセルすることが可能です。
null 対策
デリゲートは参照型なので、何もメソッドが登録されていないデリゲートはnullとなっています。そのため、そのようなデリゲートを起動しようとすると NullReferenceException 例外が投げられてしまいます。よって、デリゲートがnullになる可能性がある場合は何かしらのnull対策が必要となります。メジャーと思われる対策方法は2つ。
1つはあらかじめメソッドを登録しておくことです。デフォルトとなるメソッドで初期化しておくことでデリゲートがnullにならないことを保証します。
using UnityEngine; delegate void MyDelegate(); public class DelegateSample : MonoBehaviour { // この謎の記法については後述。何もしないメソッドでデリゲートを初期化していることを意味する MyDelegate md = () => { }; void Start() { md += こんにちは; md += さようなら; md(); } void こんにちは() { Debug.Log("Hello!"); } void さようなら() { Debug.Log("Goodby!"); } }
もう一つはnullチェックを行うことです。
using UnityEngine; delegate void MyDelegate(); public class DelegateSample : MonoBehaviour { MyDelegate md; void Start() { md += こんにちは; md += さようなら; md?.Invoke(); // md?.Invoke(); の部分はこれと同じ。"?." はnull条件演算子というもの if (md != null) { md(); } } void こんにちは() { Debug.Log("Hello!"); } void さようなら() { Debug.Log("Goodby!"); } }
ちなみに、デリゲートインスタンス名.Invoke()がデリゲートを起動するための本来のメソッドであり、デリゲートインスタンス名()はそれの簡略バージョンです。
Action/Func デリゲート群
デリゲートの機能によりメソッドを格納するための方法を手にしました。しかし、毎回デリゲート型を自分で宣言するのは少し面倒だと思いませんか?
実は、C#にはあらかじめいくつかのデリゲート型が用意されています。そのため、基本的には自分でデリゲート型を宣言することはせず、用意されたデリゲート型を使うのが一般的です。ここではよく使われるデリゲート型であるAction/Funcデリゲート群について紹介します。
Actionデリゲート群は戻り値の型がvoidのメソッドを格納できるデリゲート型で、System名前空間に属しています。
// 引数がないメソッド用のActionデリゲート public delegate void Action(); // 引数が1つのメソッド用のAction<T>デリゲート public delegate void Action<in T>(T obj); // 引数が2つのメソッド用のAction<T1,T2>デリゲート public delegate void Action<in T1,in T2>(T1 arg1, T2 arg2); // 引数が3つのメソッド用のAction<T1,T2,T3>デリゲート public delegate void Action<in T1,in T2,in T3>(T1 arg1, T2 arg2, T3 arg3); // 最大のもので16個の引数を取れる
以下のようにして使います。
using UnityEngine; public class DelegateSample : MonoBehaviour { void Start() { // Action は 引数なし、戻り値なし のメソッドを格納するためのデリゲート型 System.Action action = Hello; action(); // Action<string> は string 型の引数を1つ受け取る戻り値がないメソッドを格納するためのデリゲート型 System.Action<string> action2 = Say; action2("暑いよぉー"); } void Hello () { Debug.Log("こんにちは!"); } void Say (string message) { Debug.Log(message); } }
自分でデリゲート型を宣言する必要がなくなったため少し楽になりましたね。
一方、Funcデリゲート群は戻り値があるメソッドを格納するためのデリゲート型です。Actionと同じくSystem名前空間に属しています。
// 引数がなく、戻り値があるメソッド用のFunc<TResult>デリゲート public delegate TResult Func<out TResult>(); // 引数が1つあり、戻り値があるメソッド用のFunc<T,TResult>デリゲート public delegate TResult Func<in T,out TResult>(T arg); // 引数が2つあり、戻り値があるメソッド用のFunc<T1,T2,TResult>デリゲート public delegate TResult Func<in T1,in T2,out TResult>(T1 arg1, T2 arg2); // 最大のもので16個の引数を受け取れる
以下のようにして使います。
using UnityEngine; public class DelegateSample : MonoBehaviour { void Start() { // Func<int, int, float> は int型の引数を2つ受け取り // float 型の値を戻すメソッドを格納するためのデリゲート型 System.Func<int, int, float> func = Plus; Debug.Log(func(5, 2)); func = Minus; Debug.Log(func(5,2)); } float Plus (int a, int b) { return a + b; } float Minus (int a, int b) { return a - b; } }
ここではAction/Funcデリゲート群を紹介しましたが、C# には他にも既存のデリゲート型が多数存在します。どんなものがあるのか一度調べてみるのも良いでしょう。
デリゲートの使い所
さて、デリゲートはメソッドを格納するための型です。しかし、そんな型を作ったことによってどんな恩恵があるのでしょうか。
述語の一般化
述語とは、「XXは〇〇である」という文章の「〇〇である」の部分を表す言葉ですね。プログラミングの世界では、述語とはあるオブジェクト X が「Xは〇〇である」という条件を満たすかどうかを調べるメソッドのことを指します。以下のサンプルで考えます。
using System.Collections.Generic; using UnityEngine; public class PredicateSample { public void Process () { var list = new List<int>() {1, 40, 20, 0, 30}; Debug.Log(Count(list)); } public int Count (List<int> list) { var count = 0; foreach (var value in list) { // 10より大きい数をカウントする if (value > 10) { ++count; } } return count; } }
このサンプルでは、int型のリストを生成し、そのリストをCountメソッドに渡していますね。Countメソッドでは渡されたリストの中に含まれる10より大きい数をカウントしてその数を戻しています。
ここで、偶数をカウントするように変えることにしました。
using System.Collections.Generic; using UnityEngine; public class PredicateSample { public void Process () { var list = new List<int>() {1, 40, 20, 0, 30}; Debug.Log(Count(list)); } public int Count (List<int> list) { var count = 0; foreach (var value in list) { // 偶数をカウントする if (value % 2 == 0) { ++count; } } return count; } }
先ほどと異なる点はif文の中だけですね。
// 10より大きい数をカウントする if (value > 10) { ++count; } // 偶数をカウントする if (value % 2 == 0) { ++count; }
このif文の中の式は最終的にbool値を返します。そして、今回の場合はどちらもvalueという変数について注目していて、valueの値によってtrueかfalseかが決定されています。さて、お気付きになられましたか? この部分はデリゲートが使えそうです。てなわけで、デリゲートを使ったものがこちらになります。
using System.Collections.Generic; using UnityEngine; using System; public class PredicateSample: MonoBehaviour { public void Start() { var list = new List<int>() { 1, 40, 20, 0, 30 }; // 10より大きい数をカウント。 Debug.Log(Count(list, IsLagerThanTen)); // 偶数をカウント。 Debug.Log(Count(list, IsEven)); } // 述語 bool IsLagerThanTen(int x) { return x > 10; } bool IsEven(int x) { return x % 2 == 0; } public int Count(List<int> list, Predicate<int> predicate) { var count = 0; foreach (var value in list) { // カウントする if (predicate(value)) { ++count; } } return count; } }
大きく変わった点はCountメソッドがデリゲート型の引数を取るようになったことですね。Predicate<T>デリゲートはActionなどと同じくSystem名前空間に属している、述語のために使われることが想定されたデリゲート型です。すなわち、引数を1つ受け取ってその引数を評価してbool値を戻すメソッドを格納するためのデリゲート型です。
そして、if文の中でデリゲートを起動していますね。このように、デリゲートは述語の一般化のために使われることがあります。
イベントハンドラ
デリゲートの用法の2つ目はイベントハンドラです。これはイベントに関連があるため、イベントの項で解説します。
イベント
デリゲートの用法の2つ目はイベントハンドラです。
プロパティ
イベントについて解説する前に少しだけプロパティの話をします。オブジェクト指向言語において、基本的にメンバ変数は外部から見える状態にすべきではなく、メソッドを通してアクセスできるようにするべきとされています (いわゆるカプセル化というやつ)。でも、いちいちメソッドを用意するのは面倒です。そのため、C#にはプロパティという機能があります。プロパティとは、内部からはメンバ変数のように、外部からはメソッドのように振る舞う機能です。
using System; public class Person { private int _age; public int Age { get { return _age; } set { if (value < 0) { throw new InvalidOperationException("Age is below zero!"); } _age = value; } } } public class MyClass { public void Process() { var p = new Person(); p.Age = 10; p.Age = -1; } }
この例における Age がプロパティです。getが読み出し部分に相当し、setが書き込み部分に相当します。setの部分では年齢が負になっていないかをチェックしています。もし負の値がセットされそうになった場合は例外を投げるようにしています。このように、プロパティを使うことで想定されない値がフィールドにセットされることを防ぐことができるようになります。他にも、読み出しオンリーにしたり、複数のフィールドを組み合わせた値を戻すようにしたりすることができます。詳細はネットに上がっているプロパティの解説記事を参照ください。
イベント駆動型
プログラミングの世界では、「キーボードのスペースキーが押された」や「プレイヤーが敵を倒した」といった出来事をイベントと呼び、イベントが発生したときに行う処理のことをイベントハンドラと呼びます。そして、イベントとイベントハンドラにより駆動するプログラムのことをイベント駆動型プログラムと呼びます。
例としてキーボードのスペースキーが押されたことをイベントとしたものを考えてみましょう。
using UnityEngine; using System; // イベント待ち受け側 public class KeyboardEvent : MonoBehaviour { public Action OnSpaceKeyPressed = () => { }; private void Update() { if (Input.GetKeyDown(KeyCode.Space)) { // スペースキーが押されたときにデリゲートを起動 OnSpaceKeyPressed(); } } }
using UnityEngine; // イベントハンドラ側 public class EventHandlerSample : MonoBehaviour { private KeyboardEvent _keyboardEvent; private void Start() { _keyboardEvent = GetComponent<KeyboardEvent>(); _keyboardEvent.OnSpaceKeyPressed += IgniteWhenSpaceKeyPressed; } // イベントハンドラ private void IgniteWhenSpaceKeyPressed() { Debug.Log("スペースキーが押された"); } }
このように、デリゲートを使うことでイベント駆動型プログラミングが実現できそうです。
でもちょっと待ってください! イベント待ち受け側のクラスのデリゲートはpublicです。つまり、他のクラスからもデリゲートを起動することができてしまいます。そうすると、スペースキーが押されていないのにも関わらずOnSpaceKeyPressedデリゲートが呼ばれてしまう可能性があります。どう考えてもまずいです。
よし、ならばデリゲートをprivateにしよう。あ、でもそうしたら他のクラスがデリゲートにメソッドを登録することができなくなってしまいますね。
では、プロパティを使うのはどうか。残念ながらそれも無理です。イベントハンドラとなるメソッドを格納するためのデリゲートは、
- クラス内部からは通常のデリゲート変数と同様に扱えて
- 外部からは
+=、-=演算子によるメソッドの追加と削除のみを行える
必要があります。プロパティではこの仕組みは実現できません。
イベントはデリゲート用のプロパティ
上記の通り、デリゲートだけでイベント駆動型プログラムを書くのは危険です。そのため、C#には安全にイベント駆動型プログラミングを行うための仕組みが用意されています。それこそがイベントなのです。
using UnityEngine; using System; public class KeyboardEvent : MonoBehaviour { // イベント public event Action OnSpaceKeyPressed = () => { }; private void Update() { if (Input.GetKeyDown(KeyCode.Space)) { OnSpaceKeyPressed(); } } }
使い方は簡単で、イベントとして使いたいデリゲートの前にeventキーワードを書くだけです。これにより、そのデリゲートはクラス内部からのみ起動可能となり、クラス外部からはメソッドの追加と削除のみが行えるようになります。つまり、C#のイベントという仕組みは「イベント駆動型プログラムを実装するためのデリゲートのためのプロパティのようなもの」ということになりますね。
Unityにおけるイベント駆動型プログラミングの恩恵
ゲームプログラミングとイベント駆動型プログラミングは相性が良いですし、イベント駆動型にすることによる恩恵もあります。ここではその恩恵についての話をしましょう。
例として、プレイヤーがステージから落下したときの処理を実装することを考えます。実装項目は以下の4点です。
- 残機を減らす
- ゲームオーバー処理
- リスポーン処理
- SE再生
以下のように実装しました。
using UnityEngine; public class Player : MonoBehaviour { int _life = 3; AudioSource _audioSource; Vector3 _initialPosition; void Start () { _audioSource = GetComponent<AudioSource>(); _initialPosition = transform.position; } void Update() { if (transform.position.y <= -20.0f) { _life -= 1; if (_life == 0) { Debug.Log("Game Over!"); } transform.position = _initialPosition; _audioSource.PlayOneShot(_audioSource.clip); } } }
しかし、このコードには問題があります。
それは、色々な処理が一つのクラスにまとめられていることです。このような色々な機能が1つのクラスに詰め込まれたクラスは俗に神クラスと呼ばれており、開発規模が大きくなってくるとデバッグ、拡張性の点で問題となります。
そのため、今後のために処理を分散させることにしました。
Player クラス
- リスポーン処理
- 残機を減らす
GameManager クラス
- SE再生
- ゲームオーバー処理
public class Player : MonoBehaviour { int _life = 3; Vector3 _initialPosition; [SerializeField] GameManager _gameManager; void Start () { _initialPosition = transform.position; } void Update() { if (transform.position.y <= -20.0f) { _life -= 1; if (_life == 0) { _gameManager.GameOverProcess(); } transform.position = _initialPosition; _gameManager.PlayFallSE(); } } }
using UnityEngine; public class GameManager : MonoBehaviour { [SerializeField] AudioSource _audioSource; public void GameOverProcess() { Debug.Log("Game Over!"); } public void PlayFallSE () { _audioSource.PlayOneShot(_audioSource.clip); } }
他のクラスとの連携にはメソッドを利用しています。これで処理が分散されたので少しスッキリしましたね。
その後、開発が進んで落下時の処理を増やすことにしました。
- 残機を減らす
- ゲームオーバー処理
- リスポーン処理
- SE再生
- プレイヤーの残機UI更新 <- new!
- 画面全体のエフェクト <- new!
すると、Playerクラスは以下のようになります。
public class Player : MonoBehaviour { int _life = 3; Vector3 _initialPosition; [SerializeField] GameManager _gameManager; [SerializeField] PlayerUI _playerUI; // 新規追加 [SerializeField] ScreenEffecter _screenEffector; // 新規追加 void Start () { _initialPosition = transform.position; } void Update() { if (transform.position.y <= -20.0f) { _life -= 1; _playerUI.UpdateLifeUI(); // 新規追加 if (_life == 0){ _gameManager.GameOverProcess(); } transform.position = _initialPosition; _gameManager.PlayFallSE(); _screenEffector.PlayFallEffect(); // 新規追加 } } }
そうです、新機能を追加するために既存のクラスを編集する必要があるのです。これは拡張性の観点からすると好ましいとは言えませんね。とても面倒です。
現在の状況を図にすると以下のようになります。Playerクラスは落下したことを知らせる相手が誰なのか知っていなければなりません。Playerクラスが他のクラスに依存している、と言い換えることができるでしょう。
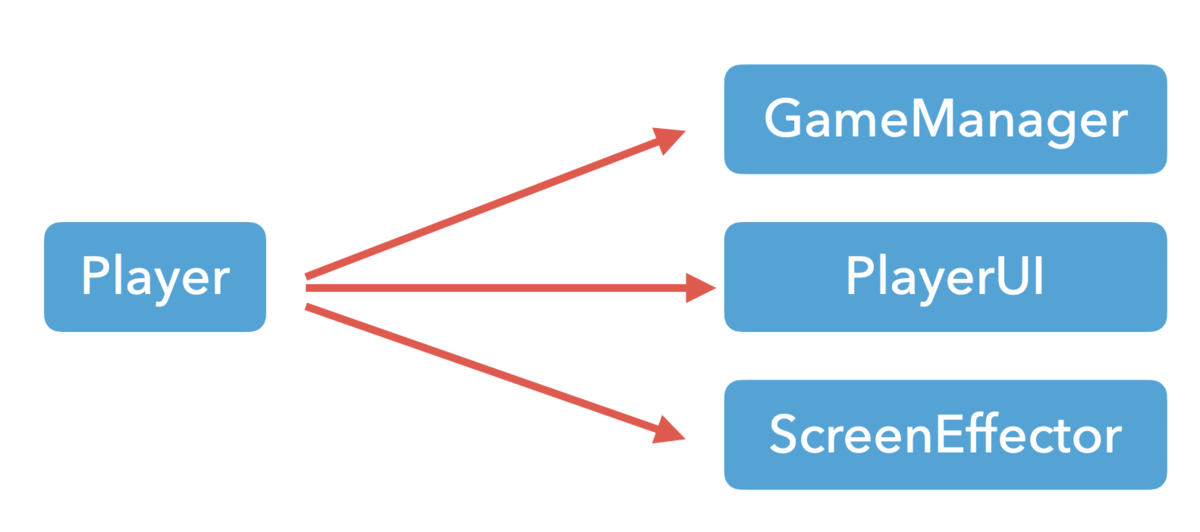
では、逆に他のクラスがPlayerクラスに依存するようにしてあげればどうか。図にするとこんな感じ。
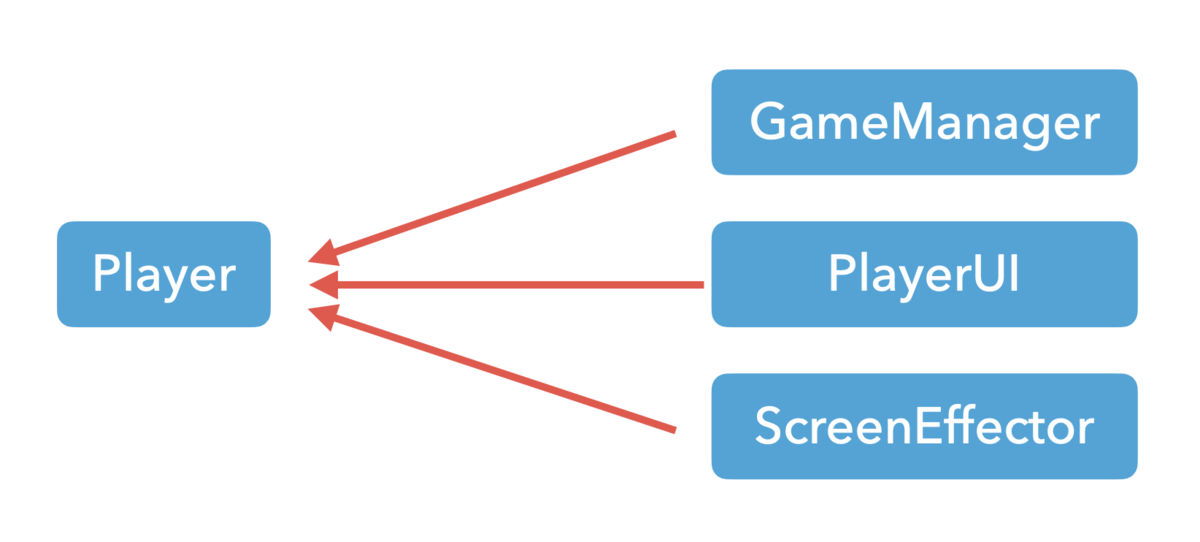
これならばPlayerクラスは他のクラスを知る必要がないので、新機能を追加したとしてもPlayerクラスに触れる必要は無くなりますね。でも、どうすれば依存性を反転させられるでしょうか。
そうです、そこで登場するのがデリゲート(イベント)なんです。つまり、こういうことです!
Player側
using UnityEngine; using System; public class Player : MonoBehaviour { int _life = 3; Vector3 _initialPosition; public event Action<int> OnFall = delegate { }; public event Action OnDead = delegate { }; void Start() { _initialPosition = transform.position; } void Update() { if (transform.position.y <= -20.0f) { _life -= 1; OnFall(_life); if (_life == 0) { OnDead(); } transform.position = _initialPosition; } } }
GameManager側
public class GameManager : MonoBehaviour { [SerializeField] AudioSource _audioSource; [SerializeField] Player _player; void Awake () { _player.OnFall += PlayFallSE; _player.OnDead += GameOverProcess; } public void GameOverProcess() { Debug.Log("Game Over!"); } public void PlayFallSE (int life) { _audioSource.PlayOneShot(_audioSource.clip); } }
Player側には落下イベントと死亡イベントが追加されました。それぞれ、落下したとき、ライフが0になったときに起動されるようになっています。そして、それらのイベントのイベントハンドラはGameManagerをはじめとした他のクラスに実装されており、他のクラスはPlayerクラスのイベントに各自イベントハンドラを登録しています。この改善のおかげで落下時の新機能を追加する際にPlayerクラスを編集する必要性がなくなりました。
このように、Unityを使ったアプリケーションはイベント駆動型の仕組みと相性が良いだけでなく、うまく扱えば開発の効率もUPさせることが可能となります。
匿名メソッド/ラムダ式
話を述語のあたりに戻しましょう。デリゲートを使うことで述語を一般化することができたという話をしたのでした。
using System.Collections.Generic; using UnityEngine; using System; public class PredicateSample: MonoBehaviour { public void Start() { var list = new List<int>() { 1, 40, 20, 0, 30 }; // 10より大きい数をカウント。 Debug.Log(Count(list, IsLagerThanTen)); // 偶数をカウント。 Debug.Log(Count(list, IsEven)); } // 述語 bool IsLagerThanTen(int x) { return x > 10; } bool IsEven(int x) { return x % 2 == 0; } public int Count(List<int> list, Predicate<int> predicate) { var count = 0; foreach (var value in list) { // カウントする if (predicate(value)) { ++count; } } return count; } }
ここで気になる点があります。それは、「デリゲートに登録するためだけにメソッドを別の場所に定義するのは面倒じゃね?」ってことです。言われてみれば確かに面倒な気がしないでもありません。特に、述語として使われるメソッドは1行で済んでしまうことが多々あります。1行で済むのならデリゲートにメソッドを登録するときに同時に登録するメソッドを定義できてしてしまえば楽でしょう。
てなわけかどうかは分かりませんが、C#にはそれを実現するための仕組みが用意されています。それが匿名メソッド、及びラムダ式です。
using System.Collections.Generic; using UnityEngine; using System; public class PredicateSample : MonoBehaviour { public void Start() { var list = new List<int>() { 1, 40, 20, 0, 30 }; // 匿名メソッド Predicate<int> predicate = delegate (int x) { return x > 10; }; Debug.Log(Count(list, predicate)); // ラムダ式 predicate = (int x) => { return x % 2 == 0; }; Debug.Log(Count(list, predicate)); } public int Count(List<int> list, Predicate<int> predicate) { var count = 0; foreach (var value in list) { // カウントする if (predicate(value)) { ++count; } } return count; } }
匿名メソッドはC#2.0から登場した機能で、デリゲートにメソッドを渡す箇所で直接メソッドを記述するための仕組みです。名前のないメソッドなので匿名メソッドなのですね。
一方、ラムダ式はC#3.0から登場した機能です。機能としては匿名メソッドと同じで、位置的には匿名メソッドのシンタックスシュガーとなります。ラムダ式が登場してからはラムダ式を使うことが一般的となっています。ラムダ式では引数の型やreturnキーワードが省略されていることが多々あるため慣れていない人にとっては読解が難しいことと思いますが、使っていくうちに慣れますのでガンガン使っていきましょう!
using UnityEngine; using System; public class LambdaExpressionSample : MonoBehaviour { void Start() { Action<string> action = (string message) => { Debug.Log(message); }; action("こんにちは"); // 変数の型が左辺値や関数の引数から推論できる場合には引数の型を省略できる action = (message) => Debug.Log(message); action("しーしゃーぷ"); // ラムダ式の中身が return 文1つだけの場合には return キーワードも省略できる Func<int, int, int> func = (a, b) => a + b; Debug.Log(func(3, 5)); } }
また、C# 6.0以降はプロパティやメソッドなどにもラムダ式が使えるようになりました。1行で書けるプロパティやメソッドであればラムダ式で書くとスマートで良きです!
private int _age; // 読み取り専用プロパティ public int Age { get => _age; } // 関数をラムダ式で記述 public int Max(int a, int b) => a > b ? a : b;
ちなみに匿名関数/ラムダ式は結構奥が深いです。もしラムダ式について詳しく知りたい場合は以下の記事などを参考にしてみてください。
https://atmarkit.itmedia.co.jp/fdotnet/extremecs/extremecs_06/extremecs_06_01.html
デリゲート/イベントのその先
LINQ
C#にはLINQと呼ばれる機能があります。LINQはLanguage Integrated Queryの略で、コレクション(配列やリスト)、XML、データベースに対する操作をやりやすくするための機能です。System.Linq名前空間にLINQのメソッドが数多く所属しています。なぜここでLINQの話をしたかというと、LINQにデリゲートが使われているためです。以下にLINQのサンプルコードを見てみましょう。
using UnityEngine; using System.Linq; public class LinqSample : MonoBehaviour { void Start() { // 文字列から文字列の配列を作る var input = "2 10 5 9 3 1 4 5 9".Split(' '); // LINQのメソッドで配列の操作をする var array = input .Select(x => int.Parse(x)) // 文字列から数値に変換 .Where(x => x >= 5) // 5以上のものだけを通す(述語) .Distinct() // 重複を除く .ToArray(); // 最終結果を配列にする // リストを表示 foreach (var value in array) { Debug.Log(value); } } }
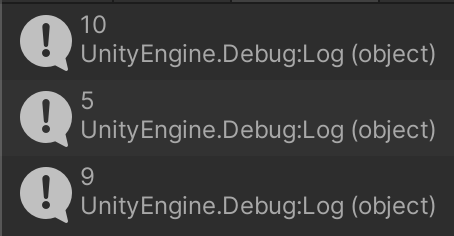
SelectやWhereなどの部分がLINQメソッドです。そして、これらのメソッドのいくつかはデリゲートを引数に取っています。そのため、LINQを使いこなすためにはデリゲートやラムダ式の理解は必須となります。
LINQはとても便利で強力な機能なので、ぜひ使えるようになっていただきたいです。
UniRx
Reactive Extension(Rx)というものをご存知でしょうか。これはLINQにおけるデータソースの範囲を「非同期」と「イベント」に広げたものです。複雑な非同期処理やイベント処理、時間が関係する処理などを、LINQの形で簡単に宣言的に記述できるのが特徴です。RXは元々MicrosoftがC#向けに開発したものでした。それが後にいろんな言語に広まっていき、今ではJavaScriptやJava、Swift、kotlin、Pythonなど数多くの言語に対応しています。(つまり、RXについて理解を深めれば他の業界に行ってもそれが武器になるということですね!)
Unityも例外ではなく、UniRxというUnity向けのRxライブラリが存在します。こちらのライブラリですが、UnityのAsset Storeで無料で配布されています。また、Unityを使っている企業の大多数が導入しているライブラリとなっており、いろんなUnity製コンテンツに使われています。
https://twitter.com/i/events/1318106823073828865
UniRxを上手に(<-ここすごく大事)使うことによって、Unityのプログラミングが大化けします。
試しに 「Unityにおけるイベント駆動型プログラミングの恩恵」 の項で使ったPlayerクラスとGameManagerクラスをUniRxで書き換えてみます。ちなみに、Reactive Xはイベント駆動型プログラミングではなく「リアクティブプログラミング」と呼ばれるプログラミング手法であり、Observerパターンと呼ばれるデザインパターンをベースにして作られています。そして、リアクティブプログラミングはイベント駆動型プログラミングの完全上位互換です。
using UnityEngine; using System; using UniRx.Triggers; using UniRx; public class Player : MonoBehaviour { int _life = 3; Vector3 _initialPosition; Subject<int> _fallSubject = new Subject<int>(); public IObservable<int> OnFall => _fallSubject; Subject<Unit> _deadSubject = new Subject<Unit>(); public IObservable<Unit> OnDead => _deadSubject; void Start() { _initialPosition = transform.position; // 落下に関するメインストリーム var fallObservable = this.UpdateAsObservable() .Select(_ => transform.position.y) .Where(y => y <= -20.0f) .Publish() .RefCount(); // 落下監視 fallObservable .Subscribe(_ => { _fallSubject.OnNext(--_life); transform.position = _initialPosition; }) .AddTo(gameObject); // ゲームオーバー監視 fallObservable .Select(_ => _life) .Where(life => life == 0) .Subscribe(_ => { _deadSubject.OnNext(Unit.Default); }) .AddTo(gameObject); } void OnDestroy() { // Subject の破棄 _fallSubject.Dispose(); _deadSubject.Dispose(); } }
using UnityEngine; using UniRx; public class GameManager : MonoBehaviour { [SerializeField] AudioSource _audioSource; [SerializeField] Player _player; void Awake() { _player.OnFall.Subscribe(life => _audioSource.PlayOneShot(_audioSource.clip)).AddTo(this); _player.OnDead.Subscribe(_ => Debug.Log("Game Over")).AddTo(this); } }
Rxにもデリゲートが多用されているのが確認できます。
GameManagerクラスの方はまだeventを使っていた名残がありますね。一方でPlayerクラスは完全に別物になっています。一番の衝撃はUpdateメソッドが消えたことですかね。メソッドチェーンの形でオペレータ(SelectとかWhereとか)を繋げることで、やりたいことがぱっと見で分かるようになるのもRxの強みです。
ただし、うまく使わないと逆に読みづらくて管理が大変なRxコード(俗称リアクティブスパゲティ)になってしまうため使用難易度はかなり高めです。その上学習コストも高いです。私自身うまく扱えていません。しかし、うまく使うことができれば非常に便利で強力な機能であることには間違いありません。
まとめ
- デリゲートはメソッドの参照を保持するための型
- 基本的にはActionやFuncといったC#に用意されているデリゲート型を使うのが一般的
- デリゲートは述語の一般化やイベントハンドラなどに使われる
- イベントはデリゲートにおけるプロパティのようなもの
- Unityではイベントを利用することで管理が楽で拡張しやすいコードにすることができる
- ラムダ式を使うことでデリゲートにメソッドを渡す箇所でメソッドを定義できる
長ったらしい記事になってしまいましたが、ここまで読んでくれてありがとうございました。私がデリゲートやラムダ式について学習し始めたときはこれらの使い所や存在意義が全く分かりませんでした。あの頃の私のような方はたくさんいらっしゃることと思います。そんな方々にとってこの記事が少しでも理解に貢献するものであれば幸いです。
参照
- https://ufcpp.net/study/csharp/sp_delegate.html
- https://ufcpp.net/study/csharp/sp_event.html
- https://csharp.keicode.com/basic/delegates-basic.php
- https://ufcpp.net/study/csharp/functional/miscdelegateinternal/
- https://ufcpp.net/study/csharp/oo_property.html
- https://www.atmarkit.co.jp/fdotnet/introrx/introrx_01/introrx_01_01.html
- https://qiita.com/Marimoiro/items/0e119b47d65bf138789a
- https://qiita.com/toRisouP/items/2f1643e344c741dd94f8